
首个人体动捕基模型SMPLer-X 在7个关键榜单上均刷新了最佳性能
2024-11-27 13:13:17玩吧吧
想要快速制作角色动画,但是没有动捕设备?快来试试SMPLer-X!
人体全身姿态与体型估计(EHPS, Expressive Human Pose and Shape estimation)虽然目前已经取得了非常大研究进展,但当下最先进的方法仍然受限于有限的训练数据集。
最近,来自南洋理工大学S-Lab、商汤科技、上海人工智能实验室、东京大学和IDEA研究院的研究人员首次提出针对人体全身姿态与体型估计任务的动捕大模型SMPLer-X。该工作使用来自不同数据源的多达450万个实例对模型进行训练,在7个关键榜单上均刷新了最佳性能。
SMPLer-X除了常见的身体动作捕捉,还能输出面部和手部动作,甚至对体型做出估计。

凭借大量数据和大型模型,SMPLer-X在各种测试和榜单中表现出强大的性能,即使在没有见过的环境中也具有出色的通用性:
1. 在数据扩展方面,研究人员对32个3D人体数据集进行了系统的评估与分析,为模型训练提供参考;
2. 在模型缩放方面,利用视觉大模型来研究该任务中增大模型参数量带来的性能提升;
3. 通过微调策略可以将SMPLer-X通用大模型转变为专用大模型,使其能够实现进一步的性能提升。

总而言之,SMPLer-X探索了数据缩放与模型缩放(图1),对32个学术数据集进行排名,并在其450万个实例上完成了训练,在7个关键榜单(如AGORA、UBody、EgoBody和EHF)上均刷新了最佳性能。
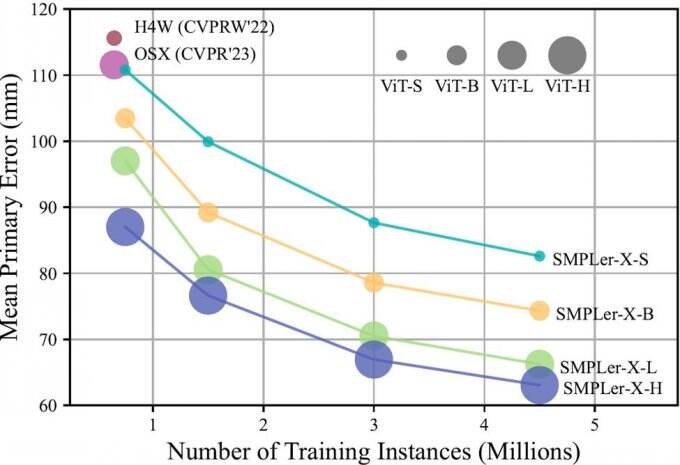
Figure 1增大数据量和模型参数量在降低关键榜单(AGORA、UBody、EgoBody、3DPW 和 EHF)的平均主要误差(MPE)方面都是有效的
现有3D人体数据集的泛化性研究
研究人员对32个学术数据集进行了排名:为了衡量每个数据集的性能,需要使用该数据集训练一个模型,并在五个评估数据集上评估模型:AGORA、UBody、EgoBody、3DPW和EHF。
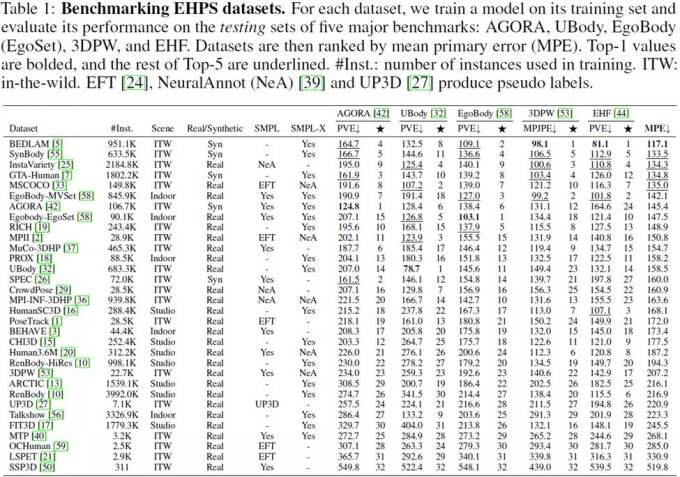
表中还计算了平均主要误差(Mean Primary Error, MPE),以便于在各个数据集之间进行简单比较。
从数据集泛化性研究中得到的启示
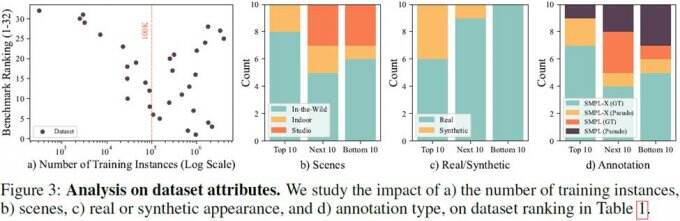
从大量数据集的分析(图3)中,可以得出以下四点结论:
1. 关于单一数据集的数据量,10万个实例数量级的数据集用于模型训练可以得到较高的性价比;
2. 关于数据集的采集场景,In-the-wild数据集效果最好,如果只能室内采集,需要避免单一场景以提升训练效果;
3. 关于数据集的采集,数据集排名前三中有两个是生成数据集,生成数据近年来展现出了强大的性能。
4. 关于数据集的标注,伪标签的数据集在训练中也发挥了至关重要的作用。
动捕大模型的训练与微调
当前最先进的方法通常只使用少数几个数据集(例如,MSCOCO、MPII和Human3.6M)进行训练,而这篇文章中探讨使用了更多数据集。

在始终优先考虑排名较高的数据集的前提下使用了四种数据量:作为训练集的5、10、20和32个数据集,总大小为75万、150万、300万和450万实例。
除此之外,研究人员也展示了低成本的微调策略来将通用大模型适应到特定场景。
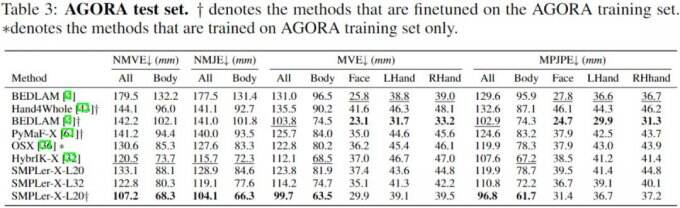


上表中展示了部分主要测试,如AGORA测试集(表3)、AGORA验证集(表4)、EHF(表5)、UBody(表6)、EgoBody-EgoSet(表7)。
此外,研究人员还在ARCTIC和DNA-Rendering两个测试集上评估了动捕大模型的泛化性。
研究人员希望SMPLer-X能带来超出算法设计的启发,并为学术社区提供强大的全身人体动捕大模型。
结果展示








同类游戏








相关文章
- 攻略
- 三星玄龙骑士电竞显示器新一代Ark正式上市

三星玄龙骑士电竞显示器新一代Ark(G97NC)以震撼的影音体验助力玩家尽情释放竞技激情。
- 苹果iOS17系统发布只有23%的iPhone用户更新
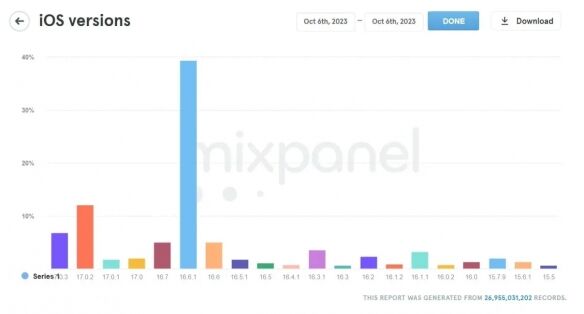
iOS17发布初期的更新率并不高,这可能是因为苹果发布了三个小版本:iOS17.0.1、iOS17.0.2和iOS17.0.3.分别用于解决不同的问题。
- 海信最强MiniLED电视来袭 海信U8KL当之无愧

从给出的具体参数来看,该款电视的分区数量多,调节的精准度更细,呈现出来的画质自然就越好。
- V社可能会对Steam Deck进一步更新硬件配置

推测该设备是经过升级的Steam Deck,该设备至少会拥有一款支持 6E (6GHz) 频段的新 Wi-Fi 模块。
- 有消息显示下一代Windows12可能会改用订阅制付费模式

据外网报道,在Windows Canary频道的INI配置文件中可以看到诸如“订阅版”“订阅类型”“订阅状态”之类的字眼。
- Meta Quest 3即将发售预期销量比预测少500万台

Meta已经为Quest 3比上一代小40%,但重量并没有变轻,处理能力提高了一倍,分辨率增强了30%。
近期热点
- 三星玄龙骑士电竞显示器新一代Ark正式上市
三星玄龙骑士电竞显示器新一代Ark(G97NC)以震撼的影音体验助力玩家尽情释放竞技激情。
- 苹果iOS17系统发布只有23%的iPhone用户更新
iOS17发布初期的更新率并不高,这可能是因为苹果发布了三个小版本:iOS17.0.1、iOS17.0.2和iOS17.0.3.分别用于解决不同的问题。
